Profiling Metadata
Currently we support automatic analysis of 5 different file types. The metadata is only populated by our automatic profiling and cannot be edited. This is because we want to preserve the objective analysis by a computer system here.
Text Files
application/pdftext/plain
The automatic analyses are listed and explained below:
- A set of simple metadata is extracted from the text file (size, PDF version, creation date, ...)
- We are trying to determine the language of the text. A score is additionally stored, which indicates the confidence.
- Keywords are extracted automatically. These are displayed on the main page of the entity.
- Key phrases are extracted using two algorithms. Currently, these are LSA and Luhn.
- A simple statistical evaluation on the distribution of charcters and number of different tokens (words, sentences, and characters).
- We perform a scan for personal data and give a score between 0 and 100, where 100 means that the resource is very likely to be GDPR relevant.
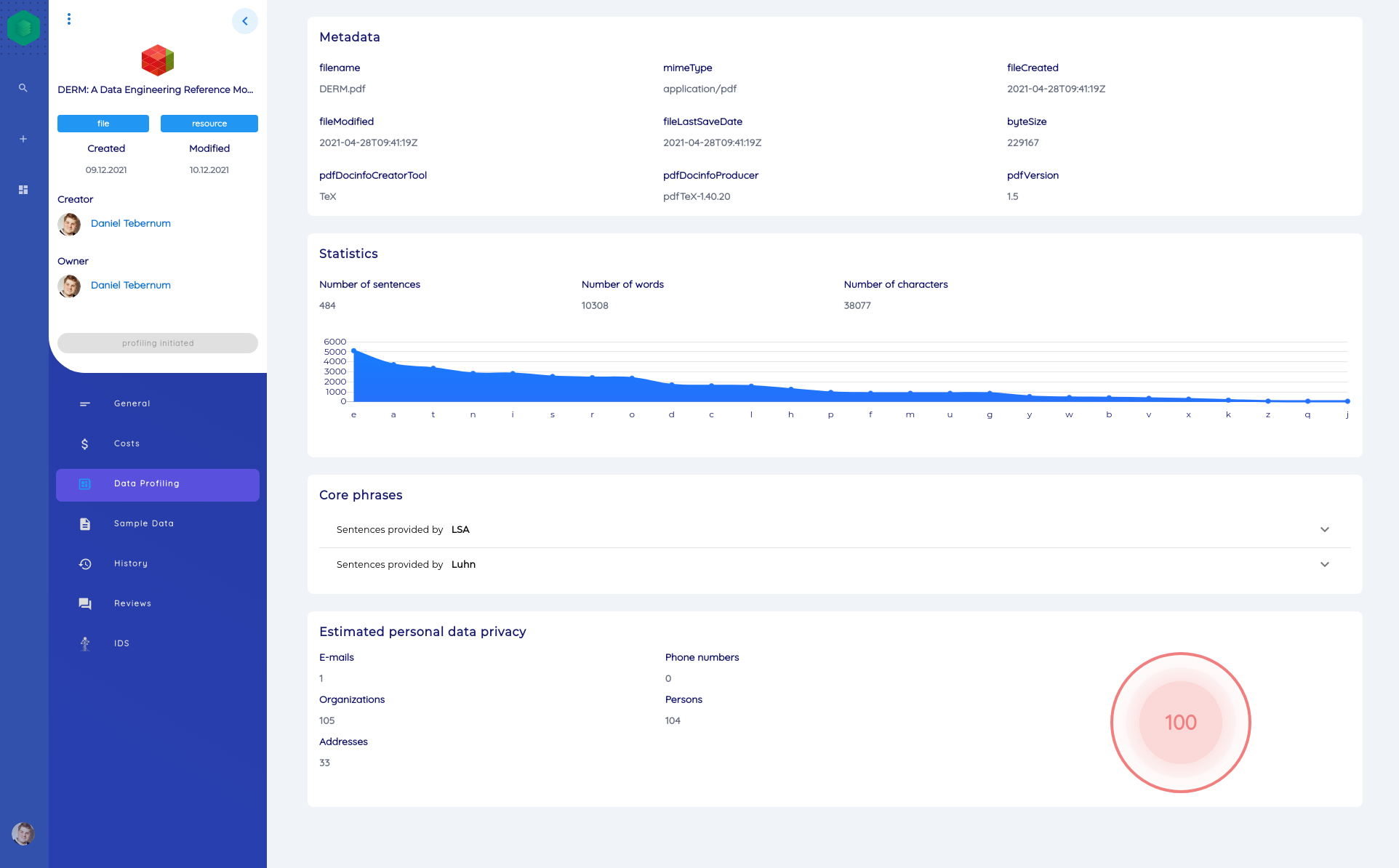
Table Files
text/csvapplication/x-sas-data
The automatic analyses are listed and explained below:
- We extract the schema of the table and visualize it.
- We perform a statistical analysis that looks at each column and extracts key metrics.
- We extract a sample set of the table to give an insight into the data.
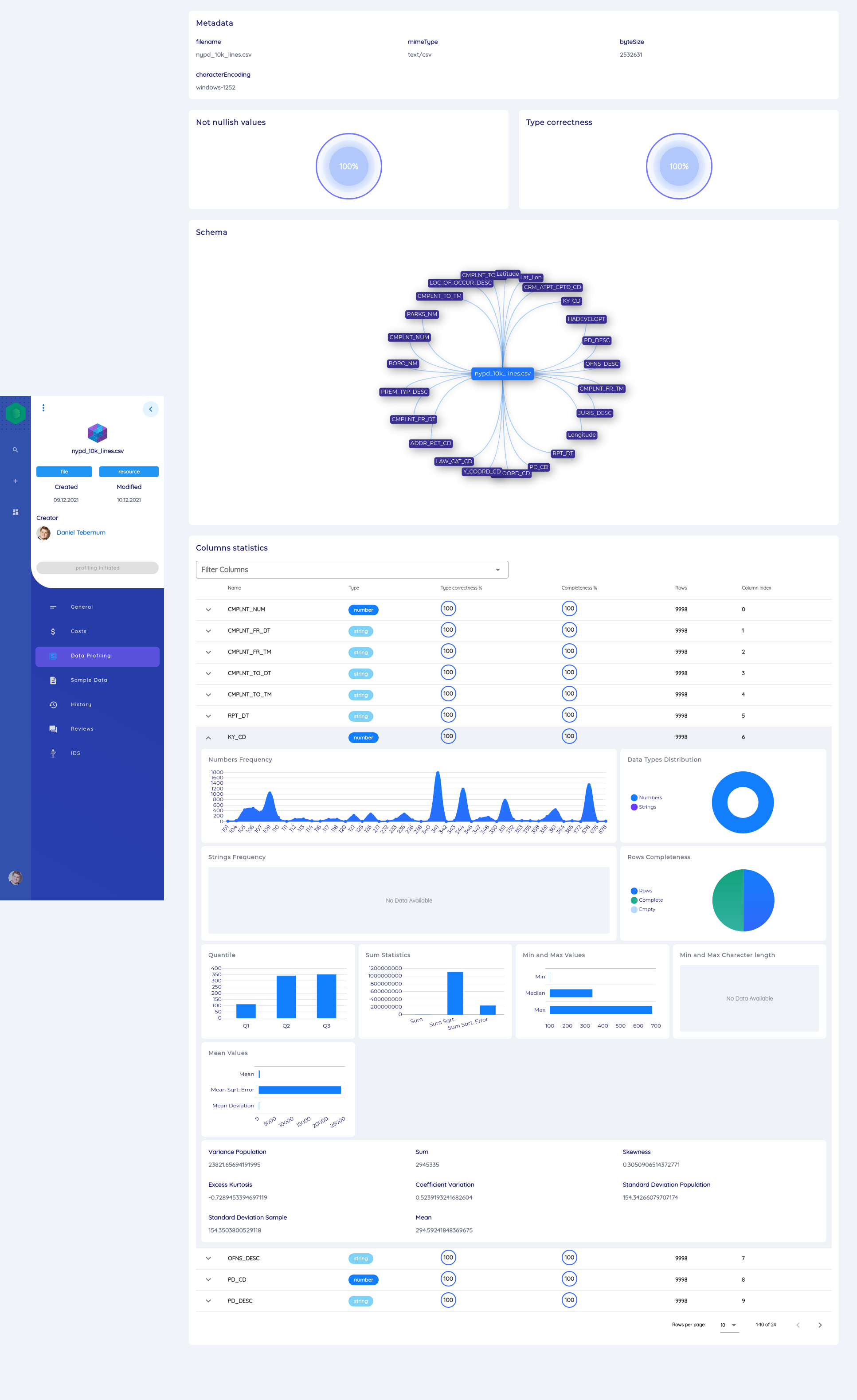
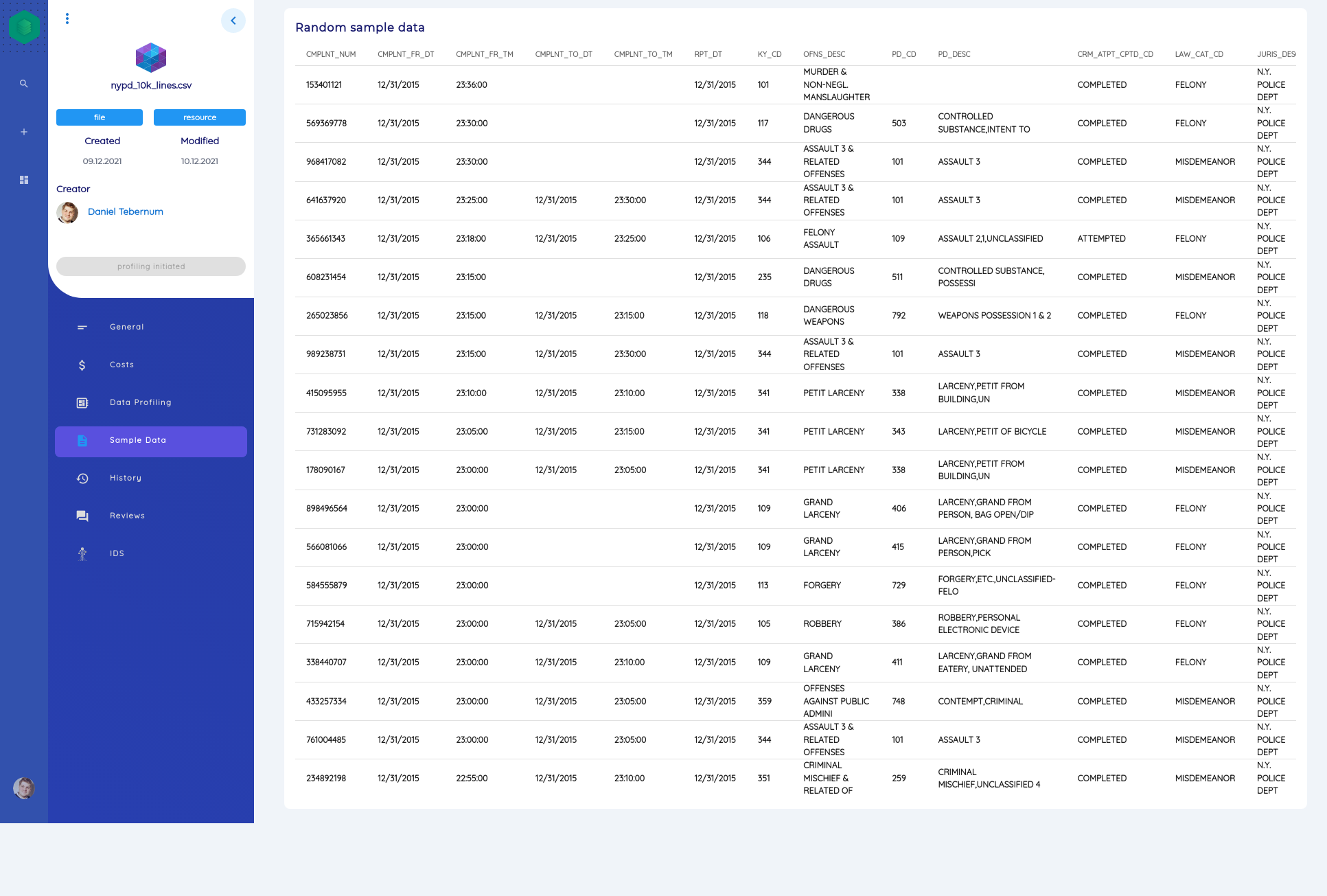
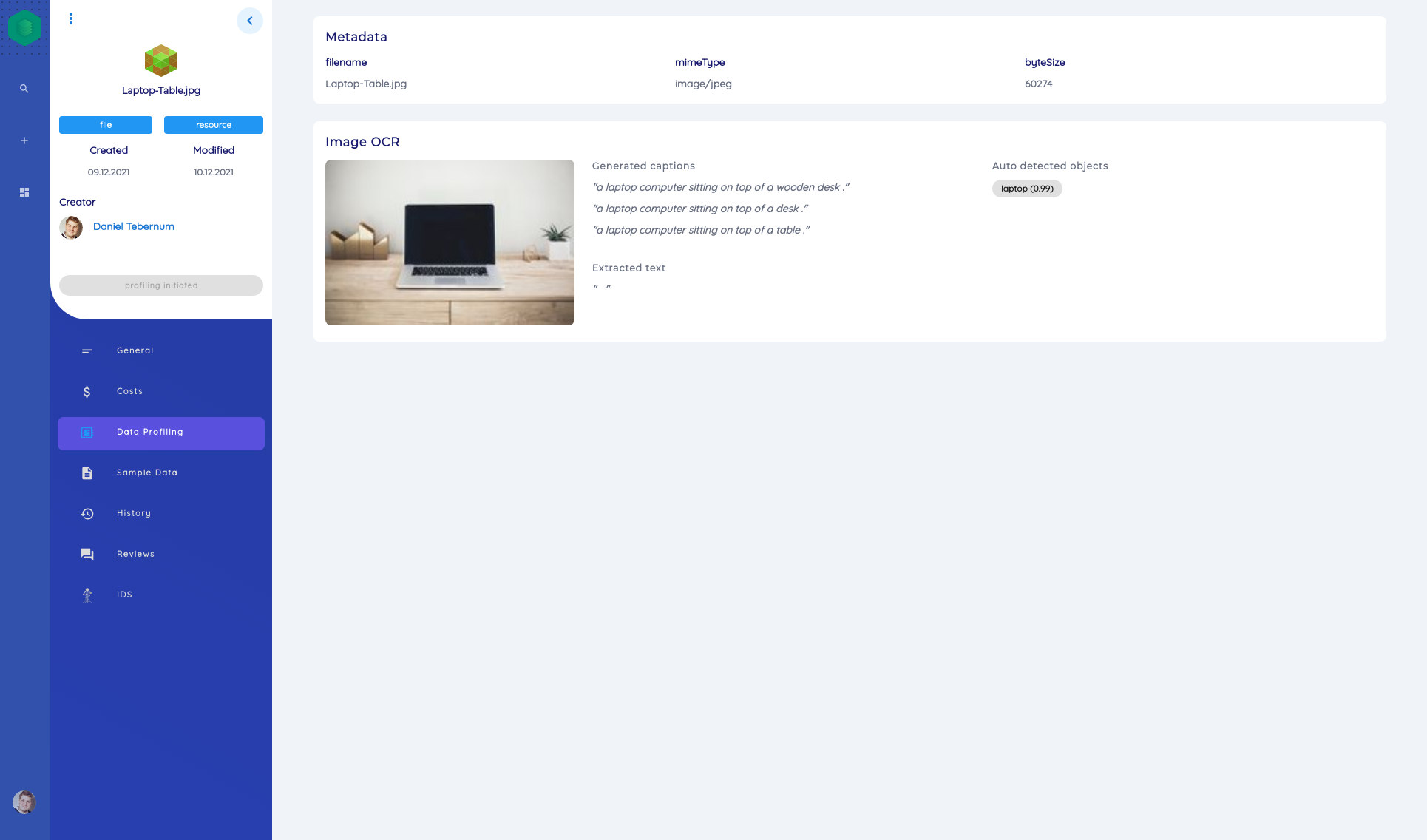
Image Files
image/jpeg
The automatic analyses are listed and explained below:
- We create a thumbnail so that you can see which image we are dealing with.
- We try to recognize the objects seen in the picture.
- We try to generate a caption for the image.
- We perform OCR text recognition on the image to make text on images search relevant in our catalog as well.
- We extract EXIF metadata, e.g. about the camera with which the photo was taken.